On Edge, Episode 4: CRISP-EML: A new methodology for embedded ML development

CRISP-EML: Lifecycle for Embedded AI Development
Introduction
The fusion of Machine Learning (ML) into embedded systems continues to revolutionize industries, unlocking unprecedented innovations. As ML continues to be integrated into every aspect of our lives, it is crucial to ensure that this integration not only breathes innovation, but also reliability, scalability and maintainability. The journey of developing in this space is intricate, requiring a nuanced understanding of both the technological and operational aspects. In this post, drawing from experience working with numerous organizations across various industries and upon insights from colleagues and collaborators, I aim to shed some light on the complex journey of developing ML applications on the embedded edge - from ideation to deployment, and beyond – with the proposal for a new and more effective framework for how to approach that journey. Developed with extensive input from experts here at SiMa.ai and across the industry, we call this new lifecycle CRISP-EML, or Cross-Industry Standard Process for Embedded Machine Learning. CRISP-EML hopes to encapsulate a fresh perspective on the nuances, personas, and requirements for the unique challenge of developing ML-driven embedded systems. It is intended to be truly representative of the industries touched by the unique challenges of building AIML-driven embedded systems — automotive, aerospace, manufacturing, and in particular, industrial automation, a sector you’ll be more hearing from us on very soon.
Through this lens, we explore the different phases of the life cycle, highlighting the key considerations, challenges and most importantly, the user personas involved – those who make an idea a reality. And in our accompanying episode of “On Edge,” we hear from a few of the voices that have had these experiences first hand.
Previous Frameworks - A Quick Review
Before introducing our lifecycle diagram, it is important to acknowledge previous works. After all, we are far from the first to try and propose such a journey. From Microsoft ML Ops, to Mckinsey, to AWS (and many others) - there have been many good approaches to formalizing the ML development lifecycle. But it is rare to find attempts at formalizing the development lifecycle of deployments within the context of ML and embedded systems. This is what we hope to address here.
This post specifically focuses on the development journey for ML embedded edge applications and expands on the core phases proposed by:
CRISP-ML(Q) - which expands on CRISP-DM (great review by ml-ops.org here)
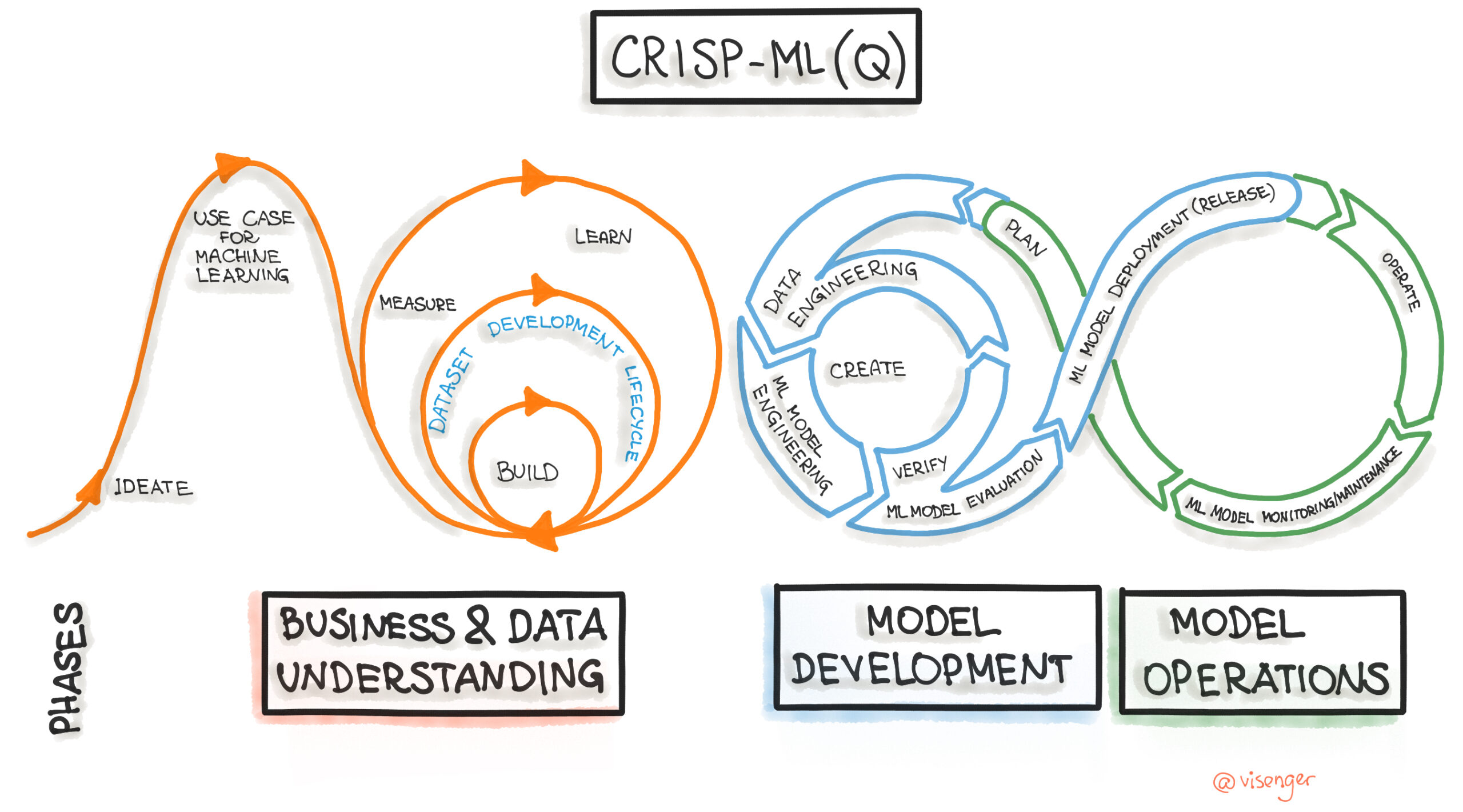
Credit: ml-ops.org
Data science life cycle management model presented by Pal Peter Hanzelik, Alex Kummer and Janos Abonyi in the MDPI article “Edge-Computing and Machine Learning-Based Framework for Software Sensor Development.”
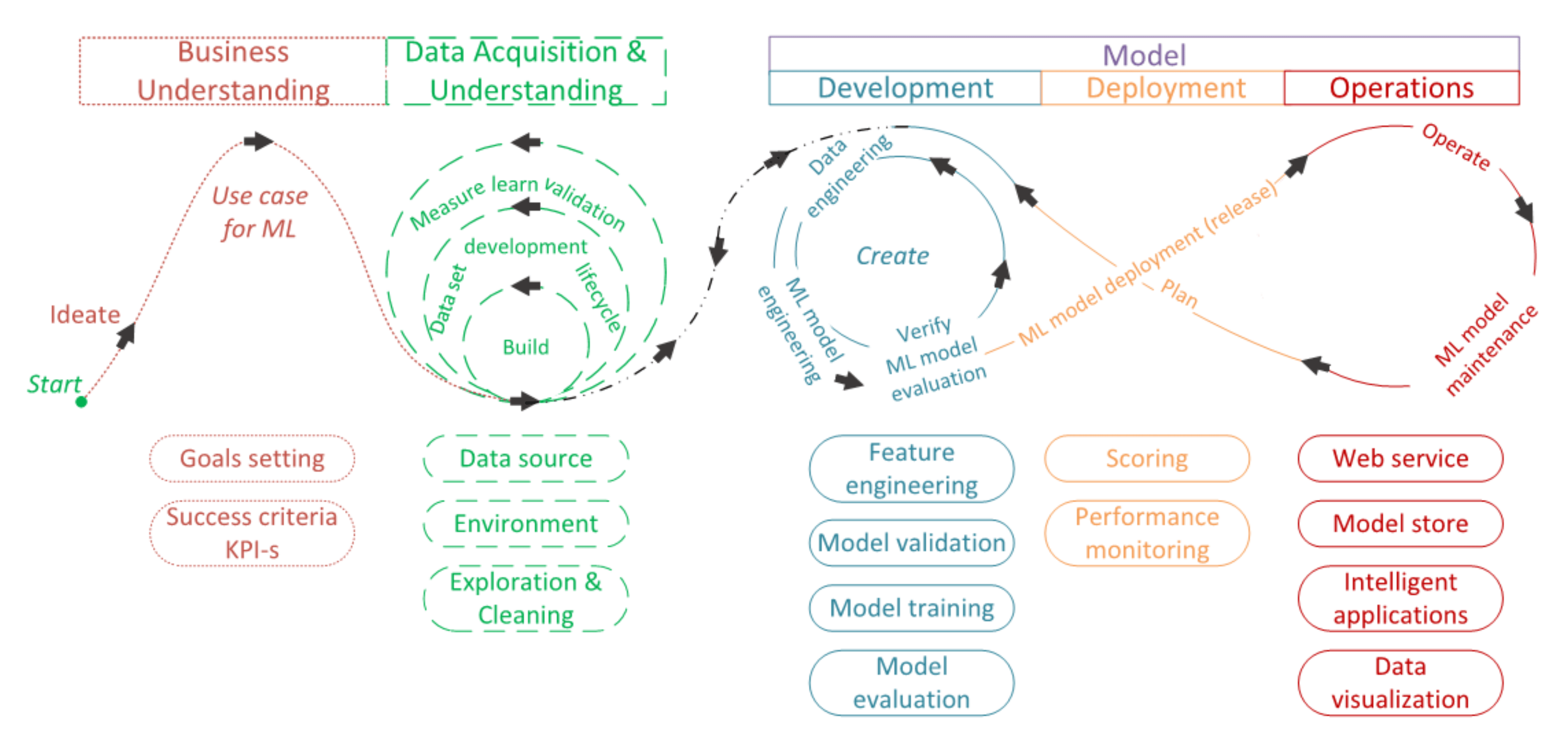
The aim is to build on the previous works by further focusing on three important aspects:
- The various personas and their essential roles at each step of the development cycle.
- The intricate cross-functional collaboration required between them during the development cycle.
- Positioning the development process through the lens of ML and embedded application development.
ML Development for the Embedded Edge - The Life Cycle Diagram
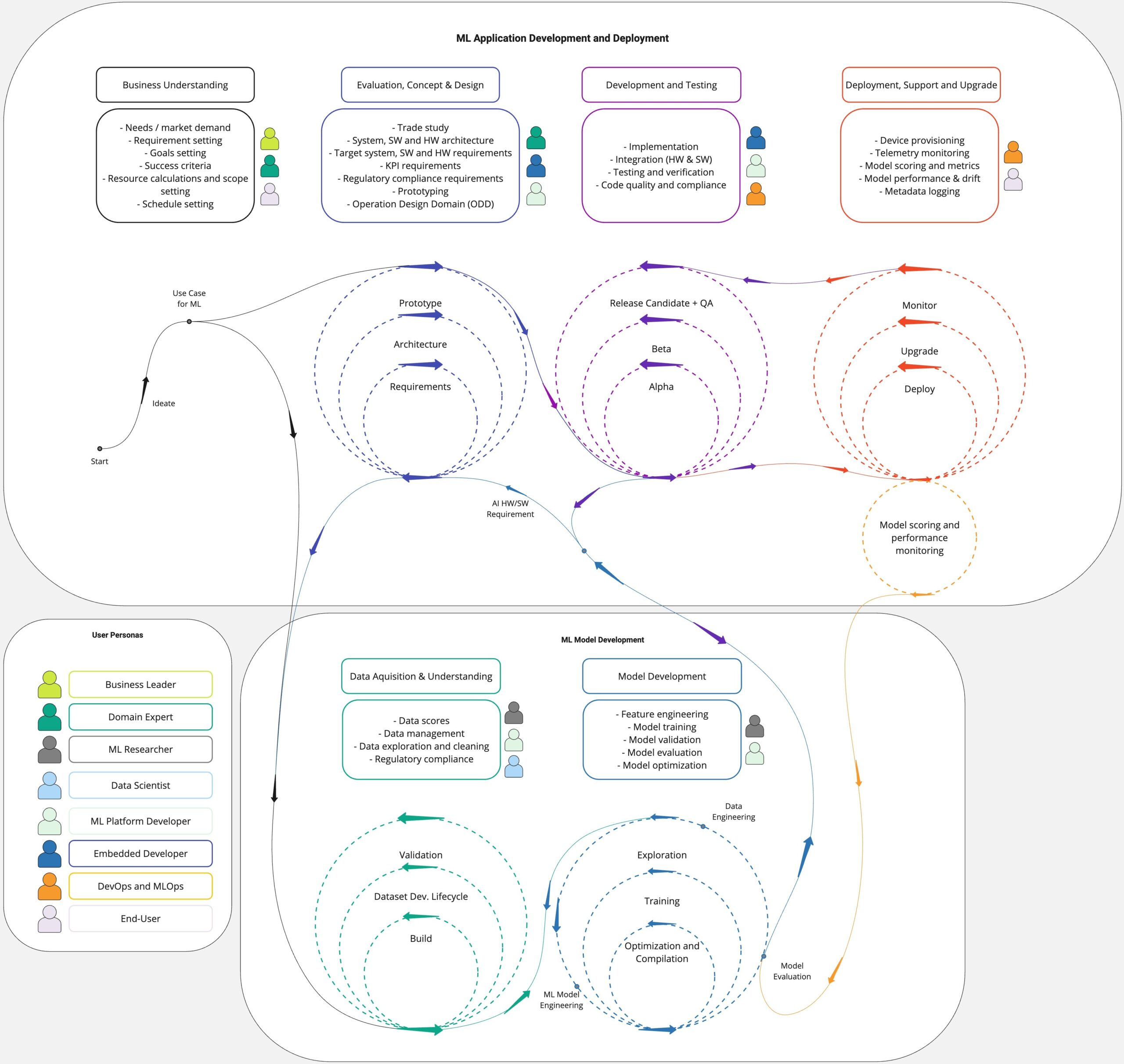
The ML development for the embedded edge life cycle diagram.
Developing solutions at the Embedded Edge involves multiple teams, owners and experts, oftentimes across multiple organizations and overlapping functional disciplines. The life cycle diagram presented here can be broken up into two major components:
- Application Development [top]
- This encapsulates all of the traditional work needed in order to plan, develop and deploy an embedded application. In this portion of the life cycle, organizations present the use case, identify business value, develop prototypes, establish system requirements, and perform application development, optimizations, integration, deployment and maintenance.
- ML Development [bottom]
- This encapsulates all of the steps required to understand the use case from an ML perspective, collect the right dataset, conduct data science activities, perform model exploration, and then proceed to train and refine these models for optimal performance.
The separation of these two functions, and understanding the interdependent relationship between ML and Application development at different stages of the life cycle, is often overlooked. In small teams, ML development and Application development may be conducted by the same team members - simplifying the interaction between functions.. But more often than not, the development of models requires expertise that is found within a different team or organization. These organizations often have teams that work on specific specializations of ML, modalities or even vertical market specializations, which adds to the complexity around coordination and communication.
If we take a step back, and abstract the diagram above, the development process can be summarized in the following way:
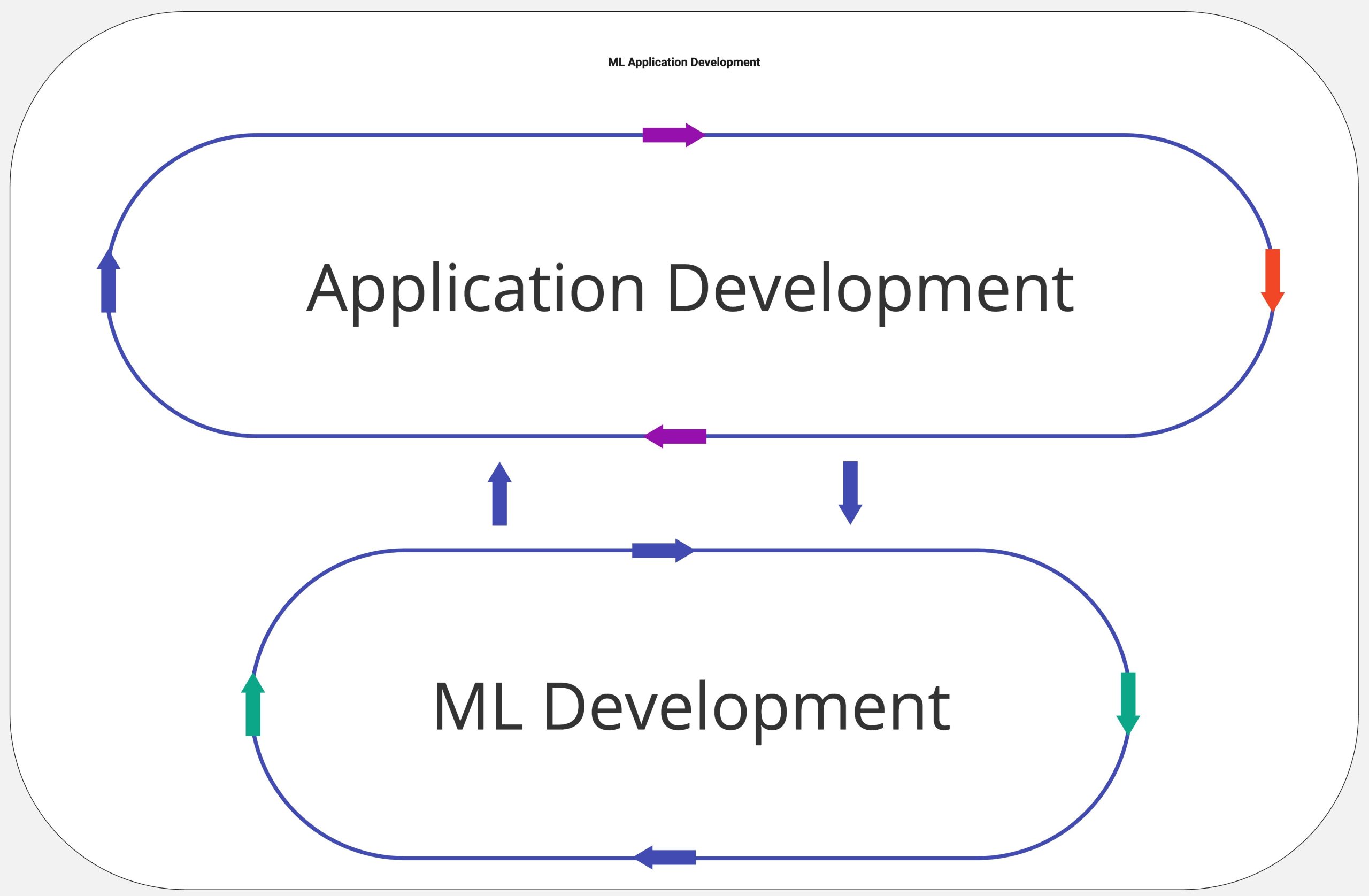
Abstracted view of ML application development
The Personas
Before we dive into the development journey, let’s take a moment to review the personas that are typically involved in successfully planning, executing and deploying an ML embedded application. Below, we have categorized them at a high level and provided some general descriptions. Later in the post, we will see how they fit into each step in the development journey.
As always, these are not all encompassing, as there are always many amazing people who make these deployments a reality (project managers, project and technical leads, architects, site managers …). But while I am sure this list can use some refinement, it should capture most of the key roles that are typically encountered, and how they might view the tasks at hand.
Persona Descriptions
Business Leader
- Mission → Drive innovation and competitive advantage ensuring it aligns with business goals and delivers a tangible ROI.
- Motivation → Identify where ML can create value, solve problems, improve efficiency/competitiveness and/or generate new revenue streams.
- Pain Points → Resource constraints, vendor lock-ins, quantifying ROI of innovations, and risk management. Limited talent pool with ML specific knowledge that fit within budget constraints.
- Technology → Utilize domain experience and domain experts to evaluate vendor technology readiness, solution cost and integration.
- Acceptance Criteria → Clear alignment with business goals and executive-level commitment. Scalability and compliance with regulatory standards.
Data Scientist
- Mission → Effectively harness and transform data through the use of statistical methods, machine learning and advanced data processing to develop capable models on the edge.
- Motivation → To extract meaningful insights from limited data and enable informed decision making and strategic advancements in ML applications. To ensure that the data used for training ML models is representative and high-quality.
- Pain Points → Balancing model complexity, accuracy metrics, latency and efficiency on embedded systems. Data availability, quality and collection is often limited and challenging to gather.
- Technology → Proficient in statistical analysis tools or languages like Python/R/Matlab/Octave and ML frameworks like TensorFlow/PyTorch.
- Acceptance Criteria → Resulting dataset availability and feature engineering, resulting model accuracy, robustness and efficiency, demonstrated improvement in application performance.
DevOps / MLOps
- Mission → To ensure efficiency and reliability of production ML application deployments through robust automation and operational practices, continuous integration/deployment practices, and implementing technical processes that align with business needs for secure and scalable production deployments.
- Motivation → Automate life cycle processes that enhance efficiency and reliability. Implement robust monitoring and maintenance of ML models and applications over time.
- Pain Points → Ensuring consistency and reliability across heterogeneous environments. Complexity of deploying and maintaining ML models within embedded systems with varying software stacks. Updating and managing ML models at scale on devices that are deployed in the field, often in remote or inaccessible locations. Dealing with data or model drift, data governance, corner case failures and unexpected behavior to name a few.
- Technology → Knowledgeable in tools and technologies for cloud to edge management, updates of SW and ML models, version control, data drift management, and performance monitoring. Includes expertise in Docker and Kubernetes, various operating systems like Windows and Linux and cloud technologies such as Azure and AWS stacks.
- Acceptance Criteria → Automation of ML application pipeline, reducing manual steps in deployment and speeding up development life cycle. Implementation of robust monitoring. Compliance with regulatory standards for security and data management. Overall system reliability, efficiency and scalability.
Domain Expert
- Mission → Provide critical context and in-depth knowledge to a specific application or domain (i.e. agriculture, healthcare, manufacturing). Critical in bridging the gap between ML and real world applications - ensuring solutions are innovative, but deeply rooted and meeting domain specific requirements and regulations.
- Motivation → Accurately identify ML solutions to existing domain specific challenges. Guide the business and development teams through domain specific requirements and constraints.
- Pain Points → Communicating complex domain-specific requirements, ensuring ML solutions do not underestimate the nuances of the domain, navigating the ROI of ML vs. existing legacy techniques and integration of new technology with legacy systems.
- Technology → Domain specific software, algorithms, sensors and overall solutions. Foundational understanding of ML concepts and how they apply to the domain. Very knowledgeable on the domain’s ecosystem solution partners, customers and suppliers.
- Acceptance Criteria → Development of innovative technology that demonstrates improvement over existing reference solutions, improves ROI, is practically viable in addressing real world needs, and meets regulatory compliance.
End-User
- Mission → To leverage the capabilities of ML embedded systems to advance business goals, enhance operational efficiencies, and drive innovation. To make jobs easier with higher reliability at a lower cost.
- Motivation → To solve business challenges in new ways, add new capabilities, improve quality and efficiency, lower costs, and gain competitive advantage or meet regulatory mandates.
- Pain Points → Difficulty in adopting and learning new technologies or qualifying them to be integrated into established workflows and critical business operations. Addressing concerns over data privacy, security, and regulatory compliance. Overcoming resistance within organizations to adopt new technologies. Lack of support.
- Technology → Have a pragmatic understanding of technology, focused on its application, benefits, and business implications. While they may not delve into technical specifics, they possess a keen awareness of how ML embedded systems can impact their roles, workflows, and the organization's bottom line.
- Acceptance Criteria → New ML applications improve quality of life for those interacting with it. Efficiency and quality are improved over previous solutions. Have full support, manuals, instructions and mitigation plans for new ML based solutions.
Embedded Developer
- Mission → Specialize in designing, developing and optimizing software for embedded systems. Crucial in integration of ML model into embedded systems in hardware-constrained environments. Deep understanding of software and hardware capabilities/limitations, ensuring that ML applications run efficiently, reliably and meet throughput and latency constraints. This includes all aspects of an application such as sensor capture, signal processing, NN pre-processing, and post-processing and other business logic.
- Motivation → Develop robust, scalable, secure and optimized ML applications across multiple embedded devices that solve specific business challenges. Collaborate with ML engineers and data scientists to integrate ML into applications with the use of efficient and innovative specialized hardware processors.
- Pain Points → Working with diverse ecosystem of hardware and software tools, often with limited support. Balancing computational demands of ML models and applications with memory and processing limitations, while delivering real-time, or close to real-time performance.
- Technology → Comprehensive understanding of embedded system architectures, operating systems and RTOS, C/C++, Rust, and Python. Understand various libraries and frameworks such as OpenCV, and GStreamer. Knowledgeable with ML frameworks and model optimization techniques to leverage hardware acceleration such as quantization and pruning. Deep understanding of hardware interfaces and protocols as well as debugging, firmware development, and ensuring the security of embedded devices.
- Acceptance Criteria → Development of scalable and maintainable software along with demonstrated ability to integrate and optimize ML models to run on edge devices. Aim to achieve real-time performance and accuracy metrics that meet business and end-user needs.
ML Platform Developer
- Mission → To be in the intersection of system design, embedded and ML development. Focuses on optimizing platforms that will support the deployment and operation of ML applications on the edge. By bridging the traditional embedded domain with the ML domain, they aim to enable sophisticated ML capabilities with limited resources.
- Motivation → To architect and refine the platforms that enable efficient, reliable deployment of machine learning models on embedded devices, ensuring that these platforms support the nuanced requirements of ML applications, now and in the future.
- Pain Points → Navigating the limitations in embedded hardware such as: limited memory, processing power, and energy consumption challenges when trying to deploy computationally intensive ML models. Trying to deploy ML hardware that is flexible and future proof.
- Technology → Machine learning frameworks such as: TensorFlow, TensorFlow Lite and PyTorch. Also solid understanding of ML toolchains such as SiMa.ai’s Palette, Intel’s OpenVino, NVIDIA's TensorRT and QCOMM’s Neural Processing SDK. Proficient in Python, and C++.
- Acceptance Criteria → Development of an ML platform that is optimized for embedded environments, demonstrating efficient model performance within hardware constraints. Achievement of benchmarks for performance, energy consumption, and resource utilization that meet or exceed project requirements.
ML Researcher
- Mission → To explore state-of-the-art ML models, and develop new algorithms, techniques, and methodologies to enhance the performance, efficiency, and applicability of ML models in embedded environments.
- Motivation → To stay at the forefront of ML technology, continually exploring new paradigms, tools, and techniques. To conduct cutting-edge research that addresses fundamental challenges in deploying ML on embedded systems that solve business goals and improves on previous solutions.
- Pain Points → Balancing theoretical research with practical applicability in embedded contexts. Difficulty in mapping state-of the-art ML models to business and system constraints. Making models resilient with limited data and long training cycles. Achieving high levels of performance metrics as required by various use cases (mAP, accuracy, F1, F2, …)
- Technology → Possess deep theoretical knowledge of ML and deep learning techniques including but not limited to deep learning, reinforcement learning, supervised and unsupervised learning techniques. Proficient in ML frameworks such as TensorFlow/PyTorch, and programming languages such as Python, R and Matlab.
- Acceptance Criteria → Development of innovative ML algorithms that are tailored for or can be adapted to embedded environments. Successful publication of research findings in reputable scientific journals and conferences. High performance metrics for ML models that improve upon existing techniques.
The Development Journey
In this section, we will take a closer look at each step of the Application and ML development phases. In doing so, we provide an overview of the phase, and what a particular phase depends on, and references to the main personas that are involved in each stage of development.
Application Development and Deployment
Business Understanding
This initial phase focuses on identifying business and market requirements, defining clear objectives, and setting the project's scope, timelines, and criteria for success. Establishing measurable goals, assumptions, requirements, and key performance indicators at this early stage is critical, as it shapes every subsequent step, influencing the project's risk management, mitigation strategies, and resource allocation.
A notable challenge at this juncture is the frequent lack of involvement from key stakeholders responsible for developing the solution. This oversight can necessitate revisiting initial requirements due to new feedback or the realization of what is feasibly achievable within the project's constraints of time and expertise. Although Domain Experts often play a pivotal role in bridging this gap in understanding, fully capturing the comprehensive scope of requirements without stakeholder input is challenging.
Depends on
A desired improvement on business vectors, regulatory requirements or competitive advantage and positioning. Does not directly depend on any other stages, but will inform subsequent stages in both the Application Development and ML Development steps. The only exception to this is when this stage is triggered by an improvement or evolution of an existing deployment currently in production.
Main User Personas
Business Leader, Domain Expert, End-User
Evaluation, Concept and Design
In this phase, potential solutions are evaluated, regulatory requirements are specified, concept designs are developed, requirements are finalized, and the system architecture is defined. We can think of this stage as the definition of the project - it involves thorough market and technical research, technical feasibility studies, and prototyping for potential HW and SW solutions.
This step is especially critical as it requires close collaboration and complex communication channels between domain experts, ML engineers, end-users, business strategists and embedded developers to accurately define the scope and feasibility of the initial concepts. For example, defining the HW constraints becomes important, as ML engineers may otherwise design models that will not be able to execute on the target HW. But if system engineers or embedded developers do not get feedback or requirements from the ML engineers, then they will not understand the sort of performance and memory requirements the ML models will require in order to meet the KPI requirements for this application. This iterative feedback loop between teams is crucial. Clear communication, compromise and sacrifices between teams is critical in a successful definition and concept design.
Depends on
This phase depends on a clear business understanding as the initial objectives and constraints will inform all plans and system design. It will also depend on regulatory compliance and the ML capabilities needed to meet business directed KPIs. As mentioned earlier, this means that there will be an iterative feedback loop between the Evaluation, Concept and Design step and ML Researchers, Data Scientists and ML Platform Development.
Main User Personas
Domain Expert, ML Platform Developer, Embedded Developer
Development and Testing
This phase is where the actual software development begins, incorporating both the application's core functionality and the integration of ML models. Development is iterative, involving continuous testing to ensure quality and adherence to requirements. ML models will continuously evolve and be released into the development team, where they will be integrated and tested as part of the application. Hardware and software integration cycles will also happen in this phase. Software releases encompass various levels of maturity from Alpha to Release Candidates. Emphasis is placed on maintaining code quality and ensuring compliance with relevant standards and regulations. Testing covers a range of needs from functionality, usability, performance, to security assessments. Feedback from these tests is crucial for refining the application, requiring effective collaboration between developers, testers, and domain experts to iteratively improve the product.
Depends on
This phase depends on clear requirements being set with concise acceptance criteria in the ‘Evaluation, Concept and Design’ phase. It also depends on the ‘ML Model Development' process, as this is where models are integrated and adapted based on system testing (as shown with purple arrows leaving the ‘Development and Testing’ phase into the 'Model Development’ stage).
Main User Personas
ML Platform Developer, Embedded Developer, DevOps and MLOps
Deployment, Support and Upgrade
This phase extends beyond the initial launch, embodying DevOps and MLOps principles for continuous delivery, integration, and monitoring. It includes device provisioning for seamless deployment across varied environments, and telemetry monitoring for real-time insights into application performance. Attention is given to model performance and drift to ensure ML models adapt over time and remain accurate - this results in feedback to 'Model Development' teams. Metadata logging is critical for traceability, auditing, and refining deployment strategies. This stage demands a proactive approach to support, requiring regular OTA updates and upgrades based on user feedback and system performance to maintain and enhance application reliability and user satisfaction.
Depends on
This phase depends mainly on deliveries from the Development and Testing phase.
Main User Personas
DevOps and MLOps, End-Users
ML Model Development
Data Acquisition and Understanding
Running parallel to application development, this phase focuses on gathering and understanding the data required for ML model training. It involves identifying data sources, collecting data sets, and performing initial data analysis to ensure data quality and relevance. In addition, it includes the meticulous process of data scoring to evaluate the quality and relevance of collected data, and robust data management practices. Moreover, strict adherence to regulatory compliance is considered, ensuring that data acquisition and handling practices meet legal and ethical standards concerning privacy and data protection. This stage is foundational for ML model development, requiring collaboration between data scientists, end users and domain experts to ensure the data accurately represents the problem domain.
Depends on
This phase depends on the ‘Business Understanding’ to begin but will be refined by the requirements and regulations set in the ‘Evaluation, Concept and Design’ stage. It will also depend on any End User dependencies if the data is procured from an ‘End-User’ or customer. The type and scope of data collected are determined by the business objectives and the specific ML problem being addressed.
Main User Personas
ML Researcher, ML Platform Developer, Data Scientist
Model Development
This phase, critical to an ML embedded application, is dedicated to developing the ML models themselves. It compasses feature engineering to enhance the predictive power of models, and selecting proper ML models, or set of models. The selection of models should be a result of close collaboration and understanding between ML Researchers, ML Platform Developers, Domain Experts and Embedded Engineers, along with the target HW and corresponding toolchain. If close consideration is not taken in this step, or if teams work independently, there is a high degree of chance that a lot of work will have to be redone by ML teams in order to reselect - or retrain - models to fit on target HW, SW and performance requirements.
Model selection is then followed by model training with prepared data, validation and evaluation to ensure model accuracy and reliability. Finally, model optimization is performed to improve efficiency and performance in embedded environments. As mentioned before, close collaboration between ML Platform Developers and Domain Experts is essential to adjust model parameters and ensure all optimizations fit agreed requirements so that the models effectively address the specific challenges of the application domain.
Depends on
Depends on the ‘Evaluation, Concept and Design’ stage to fully understand all requirements, regulations and acceptance criteria. In addition, it depends on the ‘Data Acquisition and Understanding’ phase as the training of the models is contingent on having high quality and labeled data.
Main User Personas
ML Researcher, ML Platform Developer
Conclusion
In conclusion, CRISP-EML is a proposed standard framework that seeks to bring structure to the inherently iterative and complex nature of developing ML-driven embedded systems. All teams and organizations work slightly differently, are of different sizes, and are increasingly more geographically dispersed. CRISP-EML aims to provide a compass and a map for a diverse set of organizations to embrace a standard direction, while accommodating the unique needs of each project and blends of talent and resources available. By ensuring that user personas were a central theme of the CRISP-EML, we geared it towards enhancing collaboration, efficiency, and innovation across the board - championing a cohesive and dynamic approach to embedded ML development.
In the end, CRISP-EML was developed as part of my experience at SiMa.ai and working through various embedded ML applications within our company and along with customers. As I stated previously, I expect that there are details, personas and nuances that each organization faces that are not fully captured here. Please respond with your comments, thoughts and experiences as to how you see the framework, where you think it could benefit from tweaks or enhancements, and how you think it will evolve over time. Your thoughts and comments will be invaluable, so drop us a line at OnEdge@SiMa.ai.
To kick start your embedded ML journey, SiMa.ai offers a comprehensive development kit tailored to streamline your ML integration process. Buy yours today!
Credits
In putting this initial framework together, I wanted to take a moment to thank and recognize the people that helped shape it, focus it, and enhance it. In particular I wanted to thank:
Alicja Kwasniewska - For reviewing, providing feedback and helping me explain this diagram in practical detail on our latest episode of OnEdge (link provided).
Ching Hu - For reviewing and contributing to portions of CRISP-EML from a very early stage.
Pawankumar Hegde - For reviewing and providing feedback to CRISP-EML
Ken Shiring - For reviewing and providing feedback to CRISP-EML.
Joseph Beare - For reviewing, editing, and helping make this the best post it can be.
Vikas Paliwal - For initially defining the various personas, along with their roles and overall profiles. I slightly evolved those personas into what is presented here.
Elizabeth Samara-Rubio - For introducing me to Data science lifecycle management and CRISP-ML as a way to formalize my thoughts and framework.
And of course a special thank you to Ching Hu, Maciej Szankin and Pawan Hegde for sharing their experiences with us in our latest episode of “On Edge.” Please be sure to check out the episode, and subscribe to our channel for more great content and conversation. [ultimate_video u_video_url="https://www.youtube.com/watch?v=UYdDuAPloZ4" yt_autoplay="" yt_sugg_video="" yt_mute_control="" yt_modest_branding="" yt_privacy_mode="" play_size="75" enable_sub_bar=""]