Implementing Multimodal GenAI Models on Modalix
It has been our goal since starting SiMa.ai to create one software and hardware platform for the embedded edge that empowers companies to make their AI/ML innovations come to life. With the rise of Generative AI already reshaping the way humans and machines work together with conversational AI, including in-vehicle infotainment (IVI), industrial cobots, and humanoid robots, it is inevitable that Generative AI’s universal adoption will be more impactful than the PC, browser with search, and smartphone combined.
In this blog, we describe how SiMa.ai’s software-centric machine learning system-on-chip (MLSoC) enables Generative AI models to be implemented at the embedded edge with low latency and low power consumption. We have successfully implemented multiple GenAI models on Modalix, our second generation MLSoC. These include the Llama-7B and GPT-J Large Language Models (LLMs) that process text-based queries; the Llava-7B Large Multimodal Model (LMM) that processes queries consisting of both text and images; and the Whisper-small Speech-to-Text (STT) model that converts speech to text. We are currently implementing a Text-to-Speech (TTS) model on Modalix that will convert input text into an output audio stream.
We will describe how Modalix supports conversational AI in real-time with a sub-15W system power budget that is unique in the embedded edge industry.
You can find demo videos showcasing the multimodal GenAI capabilities of Modalix here.
Support for Transformer-Based Architectures
Although Modalix was primarily designed to optimize the execution of Convolutional Neural Networks (CNNs), the Instruction Set Architecture of its Machine Learning Accelerator (MLA) also supports the optimized execution of transformer-based architectures on which GenAI models are based. The architectural features of the MLA that directly enable the optimized execution of transformers include:
-
Accelerated execution of matrix multiplication operations, which occur in the self-attention blocks of the transformer model.
-
Support for user-defined functions, which are used to implement the normalization operations that occur in transformer models (e.g., Layer Norm and RMS Norm).
-
Support for both int8 and bfloat16 precision, which enables transformer models to generate results with high accuracy; int8 precision is primarily used for matrix multiplication operations, while bfloat16 precision is used to retain the accuracy of certain layers in the model.
Llama-7B and Llava-7B are based on the decoder-only transformer architecture. Diagrams of this architecture, including the operations that make up the self-attention block, are shown below.
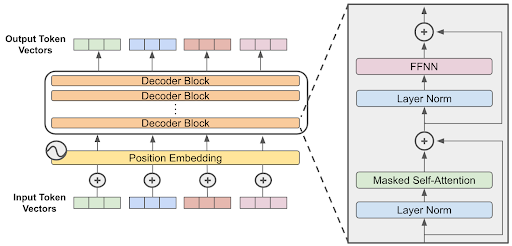
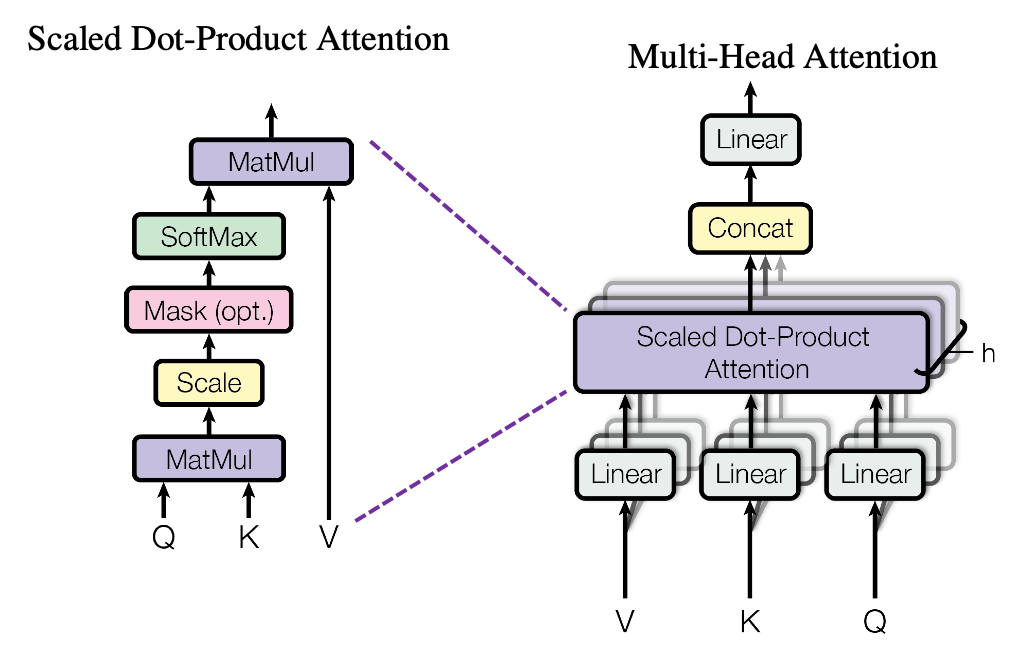
Streaming Software Architecture
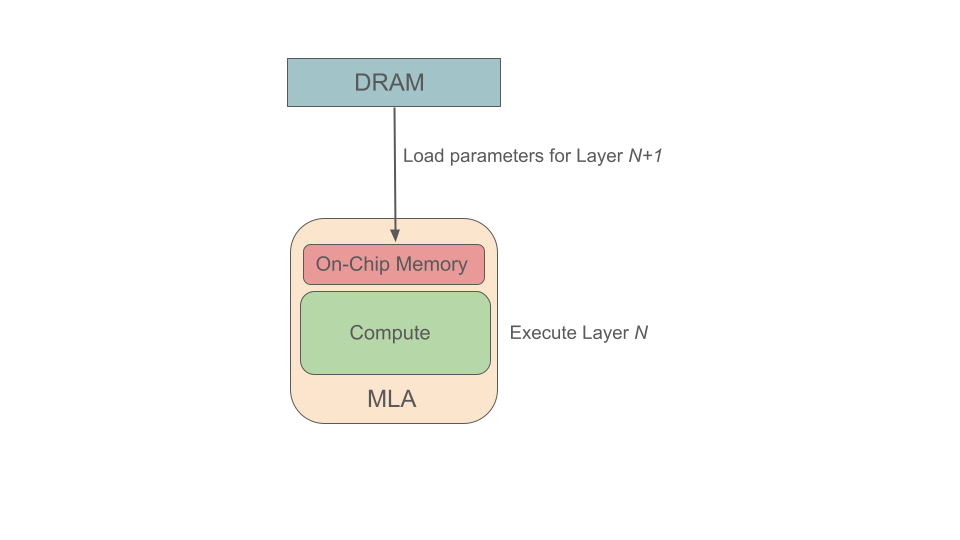
Modalix is targeted towards low latency and low power applications at the embedded edge. In order to achieve this goal, the Modalix MLA contains a limited amount of on-chip memory that is used to store model parameters and the intermediate results of computations.
The amount of on-chip memory is not large enough to store the entire 7 billion parameters of the Llama-7B LLM. However, due to the streaming architecture employed by our ML compiler, we are still able to achieve low latency for models that contain a large number of parameters. The idea behind our streaming software architecture is that while the MLA executes layer N of the ML model, it concurrently loads the parameters for layer N+1 from DRAM into on-chip memory. As a result, when layer N has finished executing on the MLA, layer N+1 can begin executing immediately since its associated parameters have already been loaded.
This streaming-based software architecture, which played a significant role in our best-in-class MLPerf benchmark results, enables Modalix to easily scale to even larger and more complex GenAI models, such as Llama-3.3-70B which contains 70 billion parameters.
Batched Execution
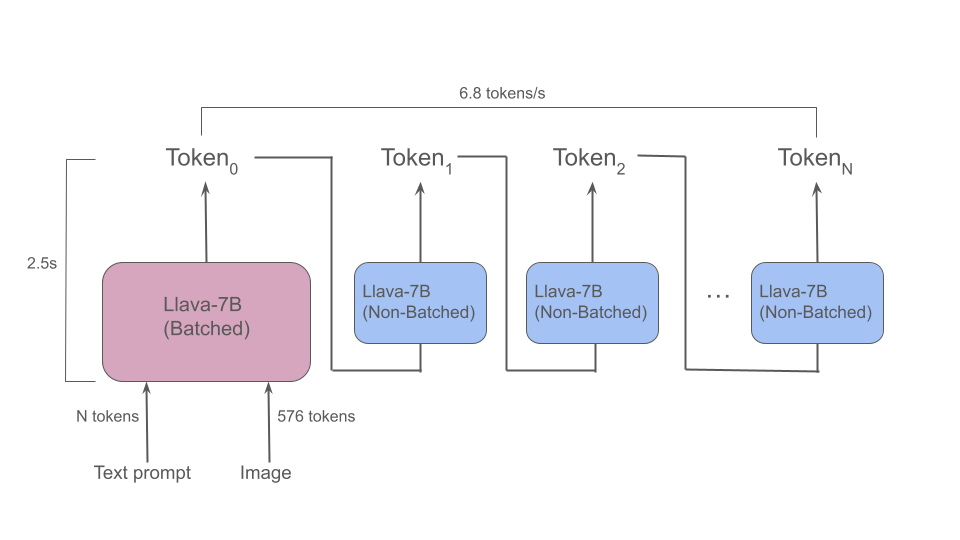
There are two performance metrics associated with GenAI model execution that we actively aim to optimize: Time-to-First-Token (measured in seconds) and Token Generation Throughput (measured in tokens per second). The input query to the model is first converted into a sequence of tokens. Once this initial sequence of tokens has been processed, the model generates output tokens one-at-a-time until the final output token has been generated. The Time-to-First-Token metric specifies the amount of time required until the first output token has been generated, while the Token Generation Throughput metric specifies the number of output tokens that are generated by the model during each second.
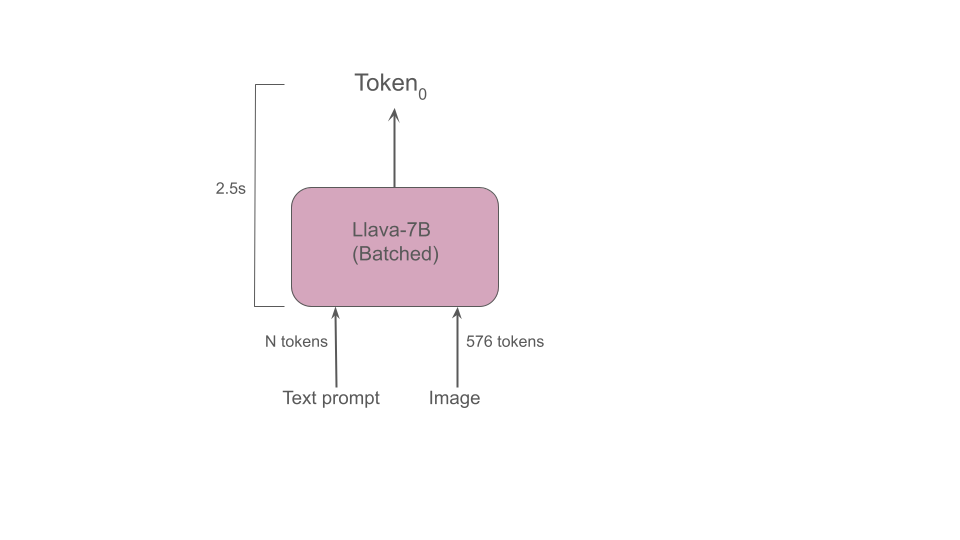
Since the input image that is passed as input to the Llava-7B LMM is converted into 576 tokens, it becomes essential to process these 576 tokens as quickly as possible in order to provide a satisfactory user experience. To achieve this, our ML compiler supports batched execution of the GenAI model, which enables multiple tokens to be processed concurrently while ensuring that all intermediate results remain in the MLA on-chip memory. Batched execution was employed by our ML compiler in our class-leading multi-stream (batch size 8) and offline (batch size 14) MLPerf ResNet50 results.
With batched execution, the processing of an image and a reasonably-sized text prompt results in an impressive Time-to-First-Token of 2.5 seconds.
Mixed-Precision Execution
We have optimized the Token Generation Throughput metric by executing operations on the MLA using int8 precision wherever feasible. We have observed that certain operators require bfloat16 precision in order to produce sufficiently accurate results, while other operators (e.g., matrix multiplications) can be executed more efficiently in int8 precision with little to no impact on overall accuracy.
While model parameters can generally be quantized to int8 precision with little effort and little to no loss in accuracy, quantizing the model activations to int8 precision is a much more arduous task. In order to quantize activations to int8 precision at compile-time, a representative dataset called the calibration dataset must first be identified. Since GenAI models are trained on huge amounts of data, it is extremely difficult to identify a representative calibration dataset that allows the activations to be quantized quickly and with sufficient accuracy. Fortunately, the presence of bfloat16 hardware on the Modalix MLA enables activations to be quantized directly on the MLA without the need for a calibration dataset.
With int8+bfloat16 mixed-precision execution, Token Generation Throughput on Modalix is currently an impressive 6.8 tokens per second. Although work is underway to further improve this metric, it should be noted that the minimum required Token Generation Throughput for an effective conversational AI experience is 3.5 tokens per second and thus, Modalix already exceeds this requirement.
Conversational AI consists of the following sequence of actions:
-
1. Capture of audio from the user.
-
2. Conversion of audio stream to text.
-
3. Capture of image from video stream.
-
4. Generation of a textual response from the converted audio and image.
-
5. Conversion of text to audio.
The Modalix hardware and software architecture enables the above conversational AI steps to be performed in real-time. Modalix enables audio to be captured from the user. Once captured, the Whisper-small Speech-to-Text model is executed and converts the audio stream to text in real-time. Modalix also enables images to be captured from a video stream via a directly connected MIPI camera. Thereafter, the Llava-7B LMM is executed on Modalix and produces a textual response to the input text and image. This textual response is then converted into an audio stream via a Text-to-Speech model that also runs on Modalix, and subsequently played back to the user.
There are multiple applications of conversational AI, including in-vehicle infotainment (IVI) systems and humanoid robots. As an example, one can imagine driving around in their car and asking the infotainment system to provide information in real-time about the building that appears on the horizon.
The ability of Modalix to support conversational AI in real-time with a sub-15W system power budget is unique in the embedded edge industry.
Conclusions and Future Work
In this blog, we have described how SiMa.ai’s software-centric MLSoC Modalix enables Generative AI models to be implemented at the embedded edge with low latency and low power consumption. Using a combination of software-based streaming, batched model execution, and mixed-precision execution, we have achieved a Time-to-First-Token of 2.5 seconds and Token Generation Throughput of 6.8 tokens per second for the Llava-7B Large Multimodal Model.
In the future, we plan to further improve the Time-to-First-Token and Token Generation Throughput metrics by extending our mixed-precision support to even smaller bit-widths (e.g., 4-bits). By storing model parameters in 4-bit precision versus 8-bit precision, we expect to significantly reduce the amount of time it takes to load parameters from DRAM into the MLA on-chip memory, with little to no loss in accuracy.
We also intend to improve model performance by implementing advanced algorithms such as speculative decoding.
As previously discussed, our streaming software architecture enables Modalix to easily scale to even larger and more complex GenAI models. Hence, we intend to implement Llama-3.3-70B, which contains 70 billion parameters, on Modalix.