LLiMa: SiMa.ai’s Automated Code Generation Framework for LLMs and VLMs for < 10W
Introduction
In our blog post titled “Implementing Multimodal GenAI Models on Modalix”, we describe how SiMa.ai’s MLSoC Modalix enables Generative AI models to be implemented for Physical AI applications with low latency and low power consumption. We implemented multiple Large Language Models (LLMs) and Vision Language Models (VLMs) on Modalix, each of which exceeds the minimum token generation throughput required for an effective conversational AI experience.
Applying lessons learned from the implementation of our initial set of GenAI models, we have designed and implemented a fully-automated framework for compiling LLMs and VLMs. This fully-automated framework, which we call LLiMa, has been integrated into our advanced Machine Learning compiler and is available to users through the Palette SDK.
In this blog, we provide an overview of the LLiMa framework. Using this framework, we have automatically compiled several LLMs and VLMs for Modalix, each of which demonstrates high performance and low power consumption. SiMa.ai’s ability to automatically generate code for a wide variety of GenAI models and support real-time conversational AI for < 10W is truly unique in the Physical AI industry.
A video showcasing the LLiMa automation framework can be found here.
LLiMa Automated Compilation Flow
Our automated compilation flow is illustrated in Figure 1 below and consists of the following sequence of steps:
- Starting with an LLM or VLM that has been downloaded from the Hugging Face platform, we build an internal model configuration that contains various attributes of the model.
- From the model configuration, we construct multiple ONNX files that implement the various components of the model.
- Each ONNX file is quantized and compiled by the SiMa Machine Learning compiler. The result is an optimized .elf binary file that runs on the SiMa Machine Learning Accelerator (MLA) with low latency and low power consumption.
- A pipeline orchestration program that runs on the MLSoC automatically coordinates the execution of the various .elf files that implement the LLM/VLM.
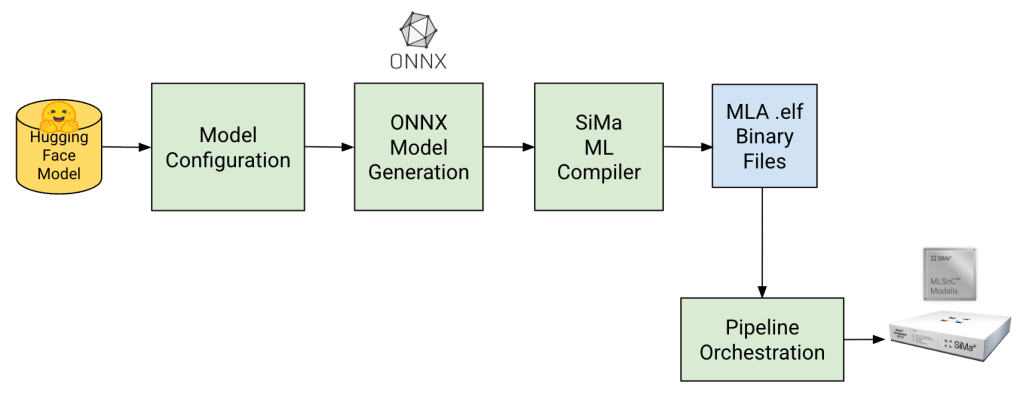
Fig 1: LLiMa automated compilation flow
With a single process, it can take up to 15 hours to compile an LLM/VLM with 7 billion parameters. However, this time can be significantly reduced by compiling the LLM/VLM with multiple processes, provided the host machine has sufficient RAM.
LLM and VLM Configuration
Each GenAI model that is hosted on the Hugging Face platform consists of a specific set of files, including a configuration file named config.json, model weights stored in safetensors format, and various files that are used by the tokenizer. The set of files that comprise the Llama-2-7b-chat-hf LLM is shown in Figure 2 below.
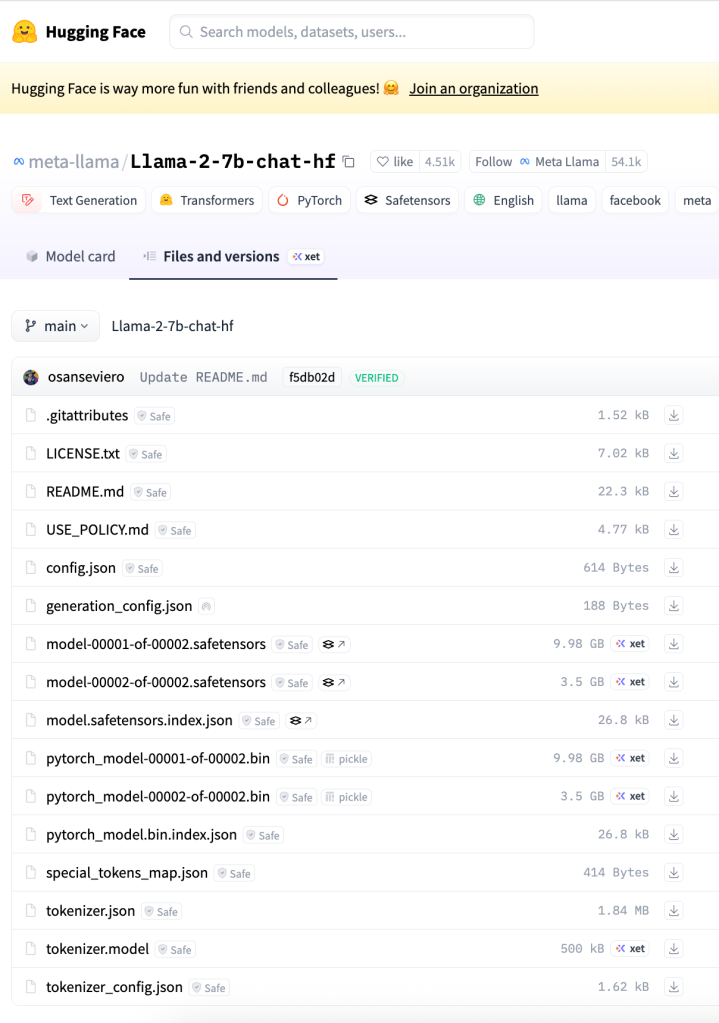
Fig 2: Hugging Face representation of Llama-2-7B-chat-hf LLM
The config.json configuration file specifies various high-level parameters of the model, including:
- Model architecture name (e.g., “LlamaForCausalLM”)
- Number of transformer layers
- Number of attention heads
- Size of an embedding
- Hidden activation function
The contents of the config.json file for the Llama-2-7b-chat-hf LLM is shown in Figure 3.

Fig 3: Llama-2-7B-chat-hf config.json
From the config.json configuration file, LLiMa constructs a SiMa-specific model configuration that takes MLA-specific constraints into account. This SiMa-specific configuration, which forms the basis of ONNX file generation, includes metadata pertaining to the following: the language model, the vision encoder (for VLMs), the Rotary Position Embedding (RoPE), the self-attention mechanism, the feed-forward network (FFN), and the tokenizer.
The SiMa-specific configuration constructed for an LLM is illustrated in Figure 4. Although this configuration consists of a large number of parameters, none of these parameters need to be modified by the user.

Fig 4: SiMa LLM configuration
ONNX Model Generation
Once the SiMa-specific model configuration has been constructed, LLiMa uses the various configuration parameters to construct ONNX files for the distinct components of the LLM/VLM: the portion of each transformer layer that accesses the KV cache (“accessor”), the portion of each transformer layer that is executed prior to accessing the KV cache (“pre-cache”), and the portion of each transformer layer that is executed after accessing the KV cache (“post-cache”).
The “pre-cache” component of each transformer layer implements QKV projection and position embedding; the KV cache accessor component implements the self-attention mechanism; the “post-cache” component of each transformer layer implements output projection and the feed-forward network (FFN).
Figure 5 below depicts how each transformer layer is segmented into distinct ONNX files.
The SiMa Machine Learning Accelerator (MLA) is a statically scheduled architecture. With this architecture, the SiMa ML compiler has full knowledge about which operations are being executed during any given cycle. As a result, the compiler is able to schedule operations such that compiled ML models execute with low latency and low power consumption.
In order for the ML compiler to have full knowledge about instruction execution, it must know the shape of each tensor. The tensors provided as input to the pre-cache and post-cache components have known shapes. However, the KV cache tensor, which is provided as input to the KV cache accessor component, increases in size as more tokens are processed.
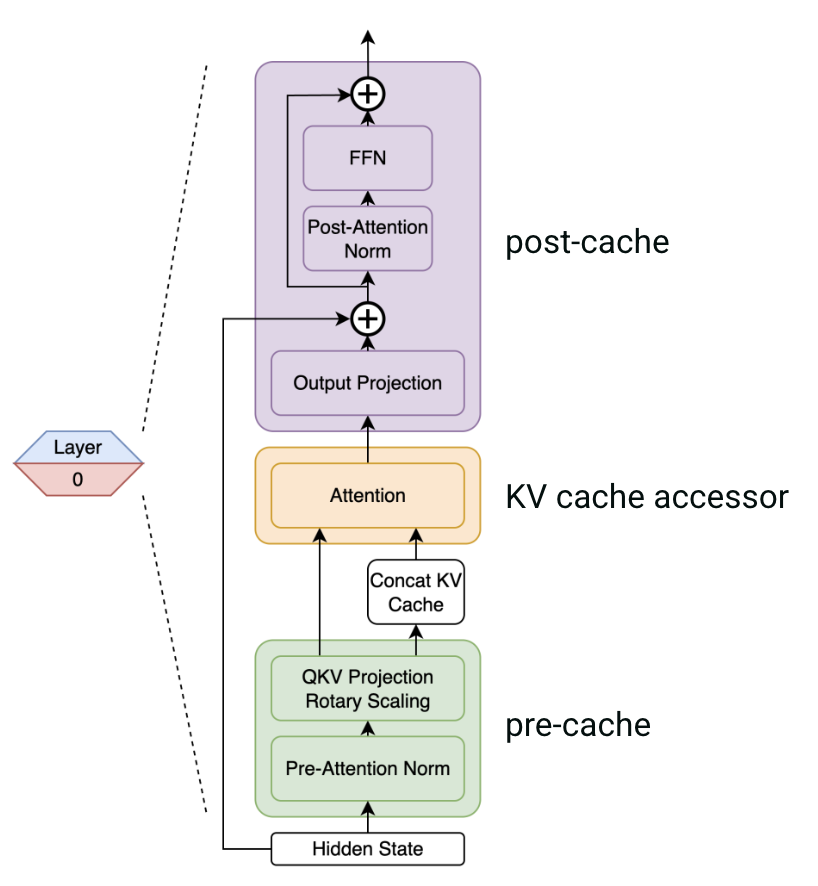
Fig 5: ONNX model segmentation
We have solved this problem by parameterizing the granularity of the KV cache tensor and KV cache accessor component. At the coarsest level of granularity, we create a single tensor for the KV cache whose size is the maximum context length, and a single ONNX file to handle this tensor. This results in significant overhead during the processing of the initial set of tokens, since the entire tensor must be operated upon as part of the self-attention computation.
At the finest level of granularity, we create multiple tensors for the KV cache, one for each token up to the maximum context length, and multiple ONNX files to handle each of these tensors. LLiMa may also be configured to use an intermediate granularity for the KV cache. For example, the first KV cache tensor and ONNX file handle the first 128 tokens, the second tensor and ONNX file handle the next 128 tokens, and so on.
ONNX Model Quantization and Compilation
Each generated ONNX file is subsequently quantized and compiled by the SiMa ML compiler, resulting in an optimized .elf binary file that runs on the MLA with low latency and low power consumption. The ML compiler is highly flexible and offers a variety of options for statically quantizing the model parameters, thus allowing users to make trade-offs between accuracy and latency. For the highest accuracy, users may store model parameters in bfloat16 precision. Suppose we have a model with X billion parameters. In this scenario, 2X GB of data would need to be loaded from DRAM into the MLA for each new output token.
Users may also choose to statically quantize model parameters to either int8 or int4 precision. In these scenarios, X GB and 0.5X GB, respectively, of data would need to be loaded from DRAM into the MLA for each new output token. While model parameters can generally be quantized to int8 precision with little to no loss in accuracy, int4 quantization may result in accuracy loss. To alleviate this loss, the SiMa ML compiler implements a technique known as block quantization.
Meanwhile, activations are unconditionally stored in bfloat16 precision and are dynamically quantized to int8 precision on the MLA, thus obviating the need for compile-time calibration. Statically quantizing activations to int8 precision would require identification of a representative dataset called the calibration dataset. Since GenAI models are trained on huge corpuses of data, identifying this representative dataset is an extremely arduous task.
Deployment and Interaction
Once the compilation phase has completed, the user must copy the generated .elf binary files and all source images to the Modalix DevKit. Thereafter, the user must log into the DevKit and invoke a pipeline orchestration program in order to interact with the LLM/VLM. This program, which runs on the Modalix APU, first loads the .elf files into DRAM. It then presents the user with a CLI prompt from where they can configure the source image to be used by the VLM. After the user has entered their textual query into the CLI prompt, the orchestration program performs the following sequence of steps:
- The user query is run through the tokenizer encoder which executes on the APU, producing a set of tokens.
- For VLMs only, the source image is passed to the vision encoder model which executes on the MLA. The vision encoder produces a set of tokens for the image (typically 576 tokens for the CLIP encoder) and returns it to the APU.
- The combined set of input tokens – system prompt, user query, and image tokens – is passed to the LLM implementation on the MLA, resulting in the first output token Token0. As described in our “Implementing Multimodal GenAI Models on Modalix” blog, we accelerate the Time-to-First-Token (TTFT) by processing these input tokens in batch.
- Each generated output token Tokeni is then passed to the LLM implementation on the MLA, resulting in the next output token Tokeni+1. This process is repeated until the final output token is generated.
- As new output tokens are generated, they are run through the tokenizer decoder on the APU, combined with previous tokens to form words, and emitted.
The LLM/VLM interaction process is highlighted in Figure 6 below.
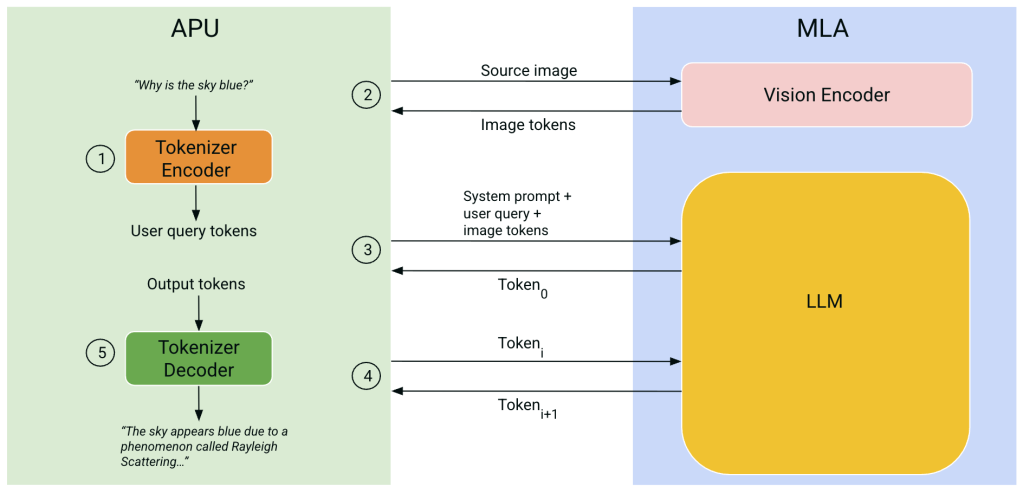
Fig 6: LLM/VLM interaction process
We are currently working on fully automating the deployment and interaction process. Generated .elf files will automatically be copied from the host machine onto the Modalix DevKit, and users will be able to interact with the LLM/VLM directly from the host machine. For VLM interaction, images will automatically be sent to the DevKit from an IP camera.
Case Studies
LLiMa currently supports the LLama2, LLama3, Gemma2, Gemma3, and Phi-mini class of architectures. LLiMa supports this class of architectures by virtue of its support for the multi-head attention, grouped-query attention, and multi-query attention self-attention mechanisms, the CLIP and SigLIP vision encoders, as well as other LLM/VLM characteristics that are encapsulated in the SiMa-specific model configuration.
To validate the LLiMa automated code generation framework, we downloaded several LLMs and VLMs from Hugging Face that belong to this class of architectures. Due to memory constraints, we focused on models containing no more than 8 billion parameters. We then proceeded to successfully compile each of these models.
Table 1 shows Time-to-First-Token (TTFT) and Tokens-per-Second (TPS) performance measurements for these compiled models. These measurements were taken assuming an input prompt size of 100 tokens for LLMs (including the system prompt), and an input prompt size of 100+n tokens for VLMs, where n is the number of tokens produced by the vision encoder for the input image. Furthermore, the maximum number of input and output tokens is 1024 for all models except PaliGemma, which has a maximum context length of 512 tokens.
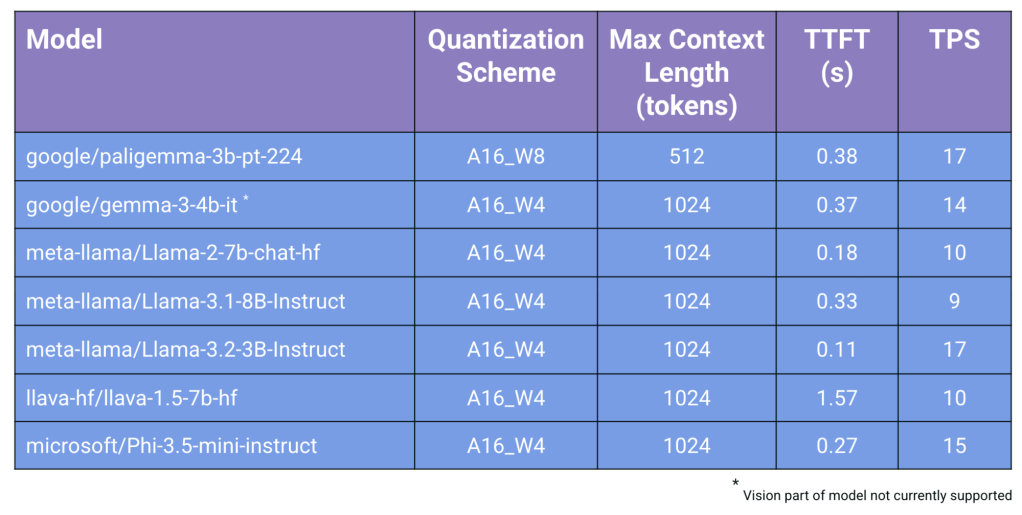
Table 1: Performance results for supported Hugging Face models, all for < 10W
The PaliGemma, Gemma, and Llava models are VLMs, while the Llama and Phi models are LLMs. Currently, only the LLM part of the Gemma model is supported. Table 1 also specifies the quantization scheme that has been employed for each model. For all models, activations are stored in bfloat16 precision and are dynamically quantized to int8 precision on the MLA (“A16”). For the PaliGemma model, weights are statically quantized to int8 precision (“W8”). Weights are statically quantized to int4 precision (“W4”) for all other models.
The results in Table 1 demonstrate that for all of the compiled LLMs and VLMs, Modalix exceeds the minimum token generation throughput required for an effective real-time conversational AI experience (3.5 TPS). We continually strive to improve the performance of GenAI models running on Modalix, and some of these performance optimization techniques will be described in the following section.
The compiled code for these models is available for download at Hugging Face. This code can be directly downloaded onto a Modalix DevKit and executed.
Conclusions and Future Work
In this blog, we have described LLiMa, a framework for the automatic code generation of Generative AI models for SiMa.ai’s advanced MLSoC Modalix hardware. Using this framework, we have automatically compiled several Hugging Face LLMs and VLMs, each of which exceeds the minimum token generation throughput required for an effective conversational AI experience. SiMa.ai’s automatic code generation capabilities for LLMs/VLMs and support for real-time conversational AI for < 10W is unique in the Physical AI industry.
Future work includes extending LLiMa to support additional architectures such as Qwen, LLaVA-NeXT, and Gemma4. We will also continue to advance our performance roadmap by implementing optimizations that improve TTFT and/or TPS:
- We will implement support for the speculative decoding algorithm, which will improve performance through the use of a smaller draft model that runs concurrently on the Modalix APU and feeds predicted tokens to the target model that runs on the MLA.
- We will investigate the feasibility of quantizing model parameters to even lower bit-widths (e.g., 2-bits and 3-bits) in order to further reduce the amount of data that needs to be loaded from DRAM into the MLA for each new output token.
- We will implement native support for pre-quantized GGUF formats so that LLMs and VLMs can run even more efficiently on the MLA.
As previously mentioned, we plan to fully automate the deployment process. In particular, we will automate the copying of all compiler-generated .elf files from the host machine onto the Modalix DevKit, and enable users to interact with the LLM/VLM directly from the host machine.
Finally, we will enhance our LLM and VLM capabilities by building support for longer context lengths with history, and incorporating retrieval-augmented generation (RAG) into the automatic deployment process.