Innovating with TVM to Address the Needs of Thousands of Customers at the Embedded Edge
Hard to overcome cloud-based challenges and a rapidly expanding market have created a huge opportunity for embedded edge AI applications. Now, with thousands of customers at the edge, innovative solutions are urgently needed to address the mismatch of performance and power requirements versus the ease-of-use needed to aid adoption. Thankfully, companies and organizations are working together like never before to innovate in areas beyond what has been previously seen in order to effectively scale embedded edge products to more than just a few token applications.
SiMa.ai and OctoML are two such companies collaborating to help edge AI system architects bring their visions to life and products to market. To do this, SiMa.ai offers a purpose-built ML platform that balances power and performance to deliver the critical frames per second per watt metric that’s at least 30X better than alternatives. SiMa.ai is also pioneering a radically different new paradigm with it’s software-first approach, focusing on open standards and ease-of-use to accelerate customers’ development and deployment velocities. Here is where the collaboration with OctoML, and their TVM deep learning compiler stack, is key. As an automated, open source unified optimization and compilation framework for AI, TVM streamlines the path from ML frameworks to target hardware. This is very important in aiding machine learning engineers in optimizing and running computations efficiently and effectively so they get the most out of the hardware.
For ML workloads, customers use a wide range of frameworks to do machine learning model development and use a wide variety of model architectures. It’s imperative to supply them with the tools necessary to avoid spending the months that are traditionally needed just to port existing legacy solutions onto a machine learning accelerator. SiMa.ai initially focused on a single neural network framework, a few types of neural network models, and a few operators. After working closely with customers on their applications and workloads though, SiMa.ai quickly realized that manual optimization of neural networks and operators is a resource-intensive effort and does not scale well.
SiMa.ai adopted Apache TVM because of its capability to support a variety of machine learning frameworks and ability to support graph partitioning, quantization and compression. In addition, a number of SiMa.ai customers and partners are working with TVM and are familiar with the TVM flow. This allowed SiMa.ai to focus on the specifics of the company’s accelerator architecture while rapidly scaling to support a large number of networks, frameworks and real-world customer applications. Customers now get push-button automated performance on 70+ networks on their architectural simulator as a result of SiMa.ai’s technology and software innovations within the TVM framework. A lot of these workloads are also seamlessly being ported to the SiMa.ai emulation platform using the same software flow. In addition, SiMa.ai’s software stack combined with TVM’s unique capabilities, allows developers to integrate and deploy neural network models from any framework using any model via any programming language, and enables SiMa.ai to support multiple customers across several vertical segments. This greatly enhances SiMa’s software-first approach, giving the company a technical leadership position when competing with non-TVM based approaches. In addition to the commercial benefits, SiMa.ai’s approach greatly de-risks the software development effort and delivers a software front-end to customers much earlier than expected.
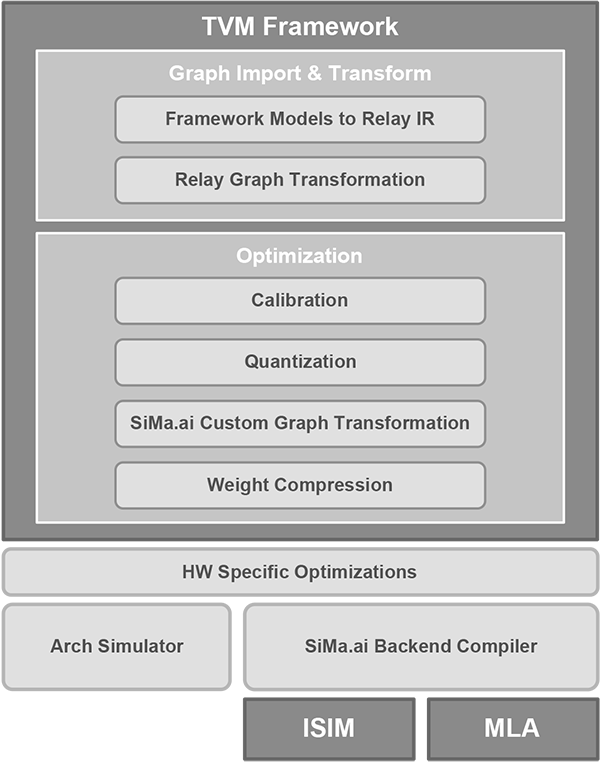
While incorporating SiMa.ai specific optimizations into the TVM framework, SiMa.ai is also using the TVM stack in the company’s SDK by:
- Starting with parsing models from TensorFlow, TensorFlow Lite, PyTorch, ONNX, Keras or MxNet to TVM’s Relay Intermediate Representation (IR)
- Creating custom operators using the Relay IR
- Partitioning complex scenarios onto each on-board accelerator prior to calling its specific compiler
- Simplifying the IR, quantizing the model, and performing graph optimization
SiMa.ai’s TVM Frontend Flow
When SiMa.ai adds new capabilities to the company’s MLSoC platform, the company also benefits from TVM’s modular design that allows for the rapid update of code and quick measure of improved key performance indicators (KPIs) over a large suite of benchmarks. In addition, SiMa.ai’s focus on software-hardware co-design has been greatly facilitated by the TVM architecture that enables the team to spend more time exploring hardware optimizations, evaluating the impact of various hardware choices, and developing a software stack that reuses and leverages TVM.
SiMa.ai is extremely pleased with the successful TVM adoption and continues to work with key TVM authors after their move to OctoML along with the TVM community who have embraced the company’s efforts. The support SiMa.ai has received from the community has helped the company improve the software offering as noted by their customer base, who have become staunch supporters of our TVM-based approach. Given all the benefits SiMa.ai has gained from using TVM and the continued support of the TVM community, SiMa.ai will continue making upstream contributions to the community as the company continues development efforts.
SiMa.ai looks forward to continuing to work with the TVM community and continuing the collaboration with OctoML to enhance the TVM stack and deliver new benefits to the entire TVM community for easier adoption at the embedded edge. OctoML is very happy to partner with SiMa.ai and other hardware vendors to enable them to fully benefit from Apache TVM. With companies like ours and so many more continuing to work together for the embedded edge market, the results will no doubt be significant.