Scaling Physical AI. Pushbutton experience.
Palette is the integrated AI application environment enabling development in days/hours, not months. Purpose built physical AI libraries, any model, and best in class performance.
Months of work.
Collapsed to days/hours.
Our software platform features Palette Neat, an agentic environment that collapses complex application timelines from months to days. The open source, purpose-built environment combines an execution library and agent workflow layer for fast development.

Seamless Migration
Seamless migration in a single prompt
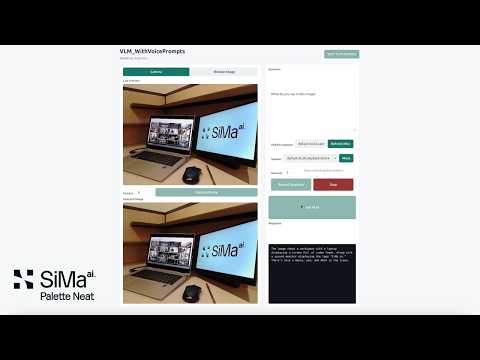
Agentic Development
Build a conversational AI pipeline in minutes

Autonomous Deployment
Low latency, on device object detection built and deployed in minutes
How it all works.
From ONNX model to production binary on SiMa.ai's Modalix MLSoC — four steps, no surprises.
Coding Agent and Dev Tools
Developers (human + agentic) write, debug, and orchestrate projects.
Palette Neat Agentic Environment
Containerized environment that builds, optimizes, and packages models for the Modalix MLSoC.
Palette Neat Library
Runtime that orchestrates inference on both host PC and the MLSoC.
Modalix MLSoC
Llama3.2 · 3B
Performance
The best performance across
the AI model spectrum.
From classic CNNs to the latest GenAI models, SiMa.ai is built for what's next.
Model Browser →
Build the next generation
of physical AI.
Get started at our Developer Center and begin shipping production-grade physical AI applications.
"Dismantling the GPU Moat to Scale Physical AI"
Krishna Rangasayee
Founder and CEO, SiMa.ai