The Silicon Behind Physical AI
Purpose-built MLSoC delivers 50 TOPS, sub-10W for vision, perception, and autonomous systems.
The performance per watt leader
Addresses any complex workload without compromise from legacy CNN's to the latest VLMs.
Heterogeneous compute, one chip
Run an entire application on a single piece of silicon. No glue chips, no external accelerators.
Swap in, no redesign needed
Pin-compatible with leading GPU SoMs — upgrade existing boards in place.
Any I/O you want
Native MIPI, USB, PCIe, UART, and more — every interface your physical AI application demands, no bridge chips required.
Built for the real world
Industrial grade, extended temperature range, and assured supply for 10+ years.
See It In Action
Proven silicon. Real deployments.
Deterministic inference running in real-world deployments.
Modalix MLSoC.
One architecture, endless scale.
50 TOPS of multimodal AI at sub-10W. Cluster multiple chips and scale seamlessly up to 200 TOPS.
Inside the Modalix MLSoC

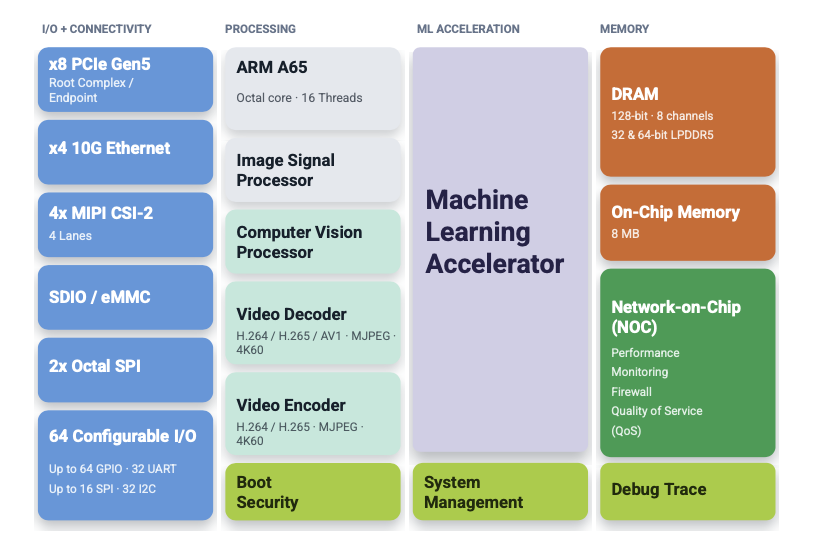
The Modalix Advantage
Accelerating ENTIRE LMM Applications on ONE Chip
Competing solutions only support these stages — requiring additional silicon for the rest.
Every form factor covered.
From SoMs that drop into existing designs, to PCIe cards for server deployments, to complete DevKits for rapid prototyping.




Ready to build on SiMa.ai silicon?
Talk to our hardware team about your deployment requirements. Volume pricing, custom configurations, and evaluation kits available.
HARDWARE
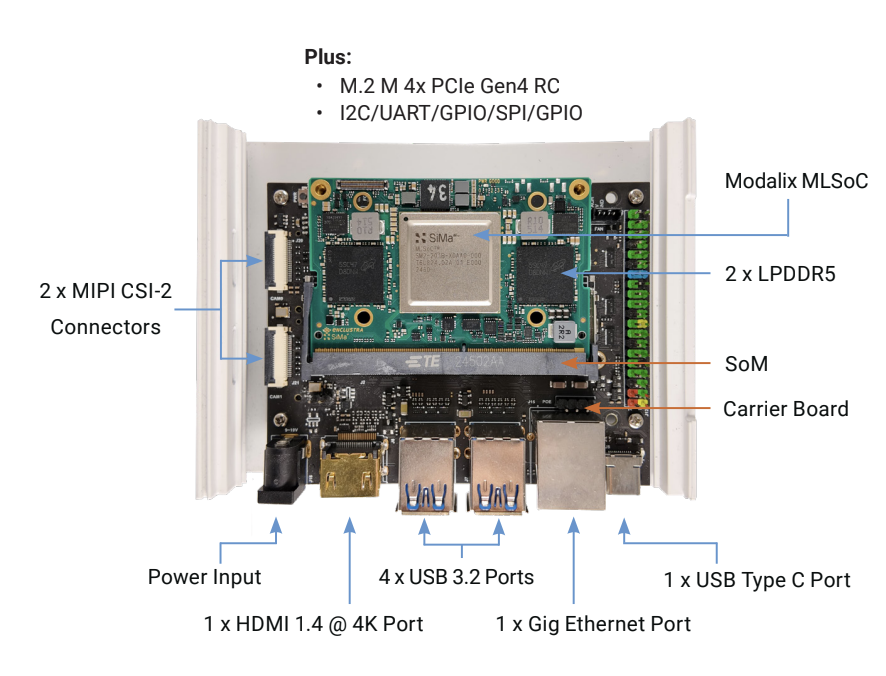
Modalix DevKit
Full ML pipeline on one SoM. Evaluate 50 TOPS at sub-10W in real hardware before you commit to production.

TECHNICAL PAPER
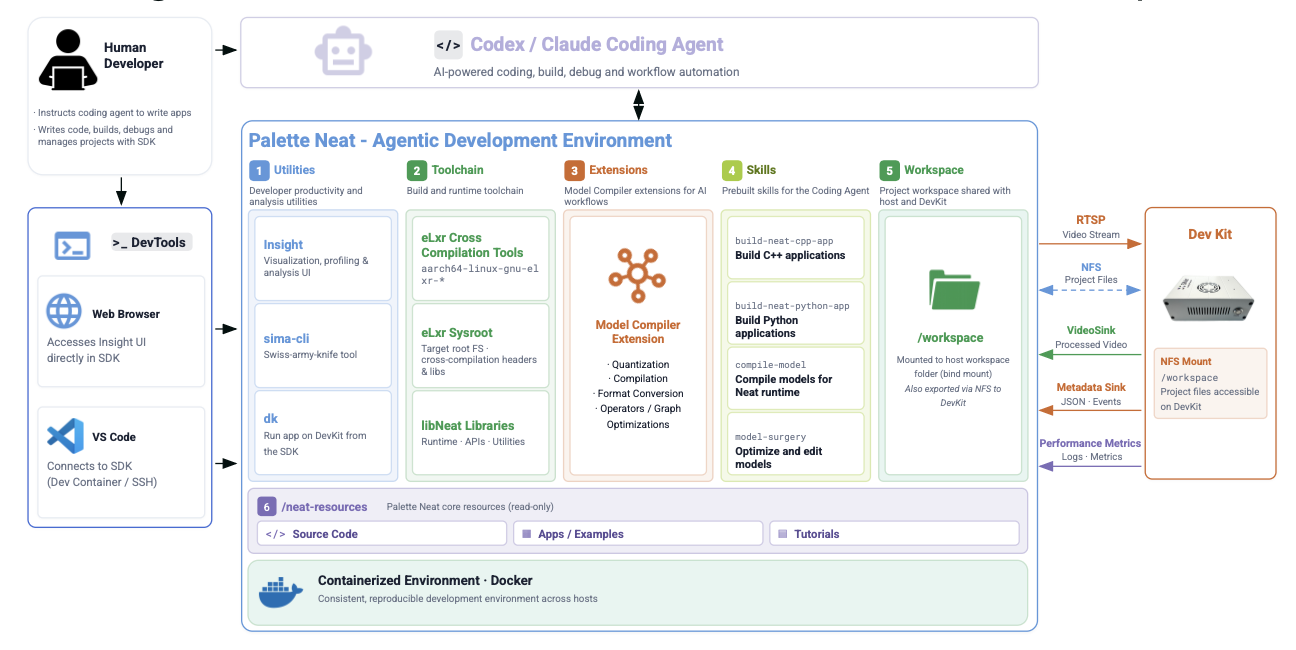
The New Software Standard for Physical AI
Learn about Palette Neat, the agentic software environment that abstracts heterogeneous compute complexity — so you go from model assets to working applications in days, not months.
1 of 3