SiMa.ai Wins MLPerf™ Closed Edge ResNet50 Benchmark Against Industry ML Leader
We recently announced the results of our first submission to the MLPerf™ benchmark. The final headline stood out loud and clear — SiMa.ai beat established legacy market incumbent NVIDIA in a head-to-head performance contest, with better latency, power efficiency, and overall performance in our debut submission.
MLCommons is a consortium of AI industry leaders, academics and researchers who have set out to build unbiased benchmarks to enable end users to compare performance of one ML product with another. Its premier benchmarking competition, known as MLPerf™, evaluates solutions on an equal playing field and includes a vendor peer review component. It’s unusual for a startup to compete, let alone emerge victorious in any capacity as many of the legacy vendors have been investing years of engineering effort fine tuning their submissions with infinite resources to ensure they reign as champions in this legendary competition.
SiMa.ai is the first startup to achieve the rare distinction of beating established ML leaders on their own turf at MLPerf™, namely NVIDIA, in the Inference v3.0 Closed Edge ResNet50 Single Stream Benchmark, which details how much energy is consumed per frame of video, measured in millijoules.1
Simply put, the SiMa.ai MLSoC compiled results outperformed NVIDIA Orin with hand coded software for edge ML top power efficiency. Our first generation is based on TSMC 16 nm technology and is two generations behind NVIDIA’s latest Orin AGX. Despite this process node disadvantage, we are able to beat NVIDIA on both performance and power without need for any hand tuning of benchmarks. The advantage that our purpose built hardware architecture brings to bear for ML at the edge is as clear as it is transformative.
How does MLPerf™ benchmarking work?
We think of MLPerf™ as the Olympics of AI performance and power efficiency. The test measures Frames per Second (FPS) over the average power consumed for ten minutes to determine a power efficiency rating measured in FPS/Watts. For the MLPerf™ 3.0 submission, we participated in the MLPerf™ ResNet50 benchmark. ResNet50 is the most widely used network for benchmarking ML inferencing processors and the standard for like-for-like comparisons. Here is the set-up we used to run our test:
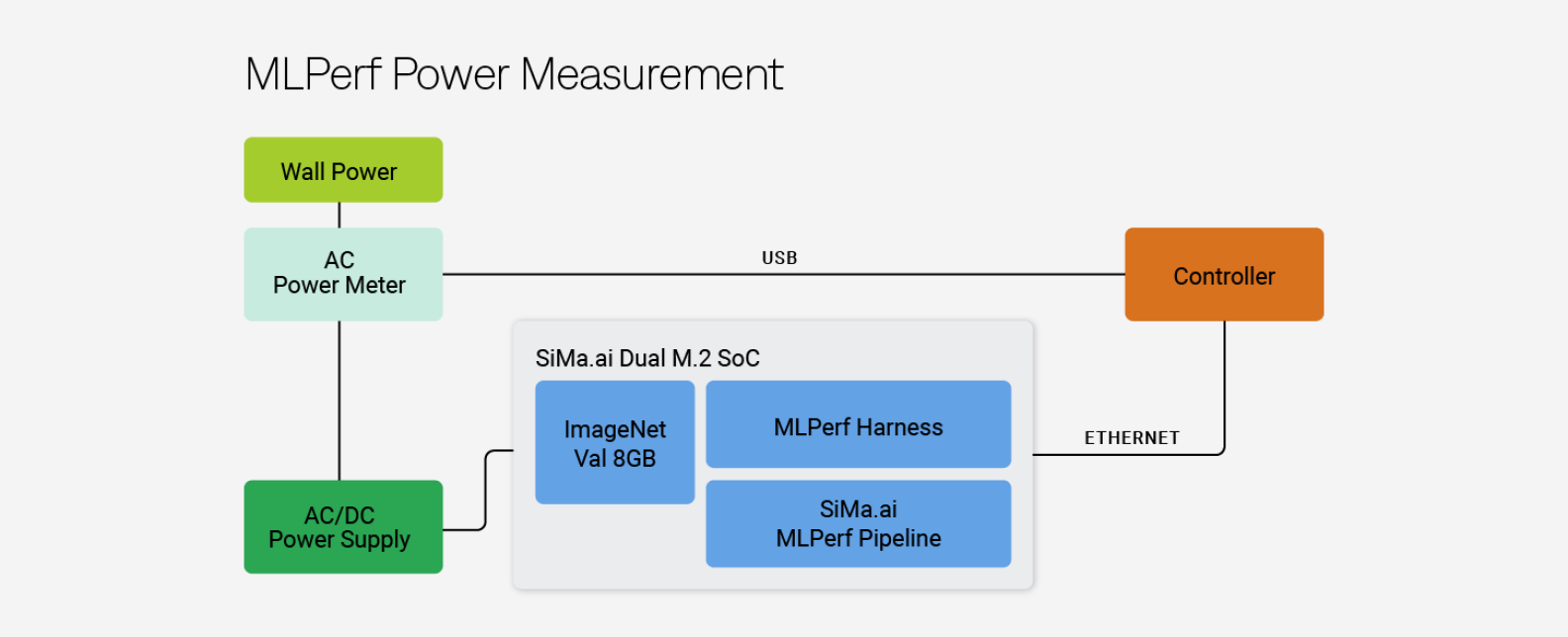 Each submitting organization loads the network (in this case Resnet50), then quantizes the model using the calibration data, and finally compiles the model. Once all participants complete their individual benchmarking, the results are sent to MLPerf™ where they are peer reviewed by a committee for accuracy and performance. Company peers review their group’s set-up and scores.
Each submitting organization loads the network (in this case Resnet50), then quantizes the model using the calibration data, and finally compiles the model. Once all participants complete their individual benchmarking, the results are sent to MLPerf™ where they are peer reviewed by a committee for accuracy and performance. Company peers review their group’s set-up and scores.
Per MLPerf™ rules, no hidden card cage or other electronics to off-load any of the work are allowed. To complete our submission test, our hardware set-up that incorporates SiMa.ai's production Dual M.2 platform with an Ethernet based carrier card was connected to a power supply via a power meter to measure the wall power, while the data was inputted via an ethernet cable. We had a couple of attending SiMa engineers facilitating the submission. This is in contrast to the other submitting teams, which have dedicated divisions or groups of hundreds of engineers dedicated to pursuing their benchmark submissions.
What did our benchmark results demonstrate?
On a Frames/Second/Watt basis SiMa offers a notable advantage over NVIDIA. Particularly at the edge, it comes down to power and latency. Let’s dig into the details:
When we cite MLPerf™ results, we're generally referring to the Inference v3.0 Closed Edge Resnet50 Single Stream Benchmark for our MLSoC DualM.2 Evaluation Kit, which details how much energy is consumed per frame of video, measured in millijoules. As you can see here (click on Closed - Power tab to see how SiMa fared), SiMa's chip registered 15.29mJ per stream2, while NVIDIA's Orin AGX registered 22.19mJ per stream3 in the same MLPerf™ Inference 3.0 benchmark. Across tests, SiMa beats NVIDIA Jetson AGX Orin (MaxQ, TensorRT) on power efficiency for both Single Stream and Multi-Stream scenarios.4
SiMa.ai submitted a batch size 1 (single camera) latency of 1.2 mSec5 and with a batch size 8 (compute processing from 8 camera frames in a single batch) of 3.7 mSec.6 Both these numbers beat the NVIDIA Jetson AGX Orin by a significant margin.7 Many edge devices are battery operated. Some are very compact in size and therefore require ultra-low power and an extremely compact form factor. SiMa.ai MLSoC delivered uncompromising performance at the lowest power. This is the first time a start-up was able to unseat the incumbent vendor (NVIDIA) with higher FPS per watt efficiency.
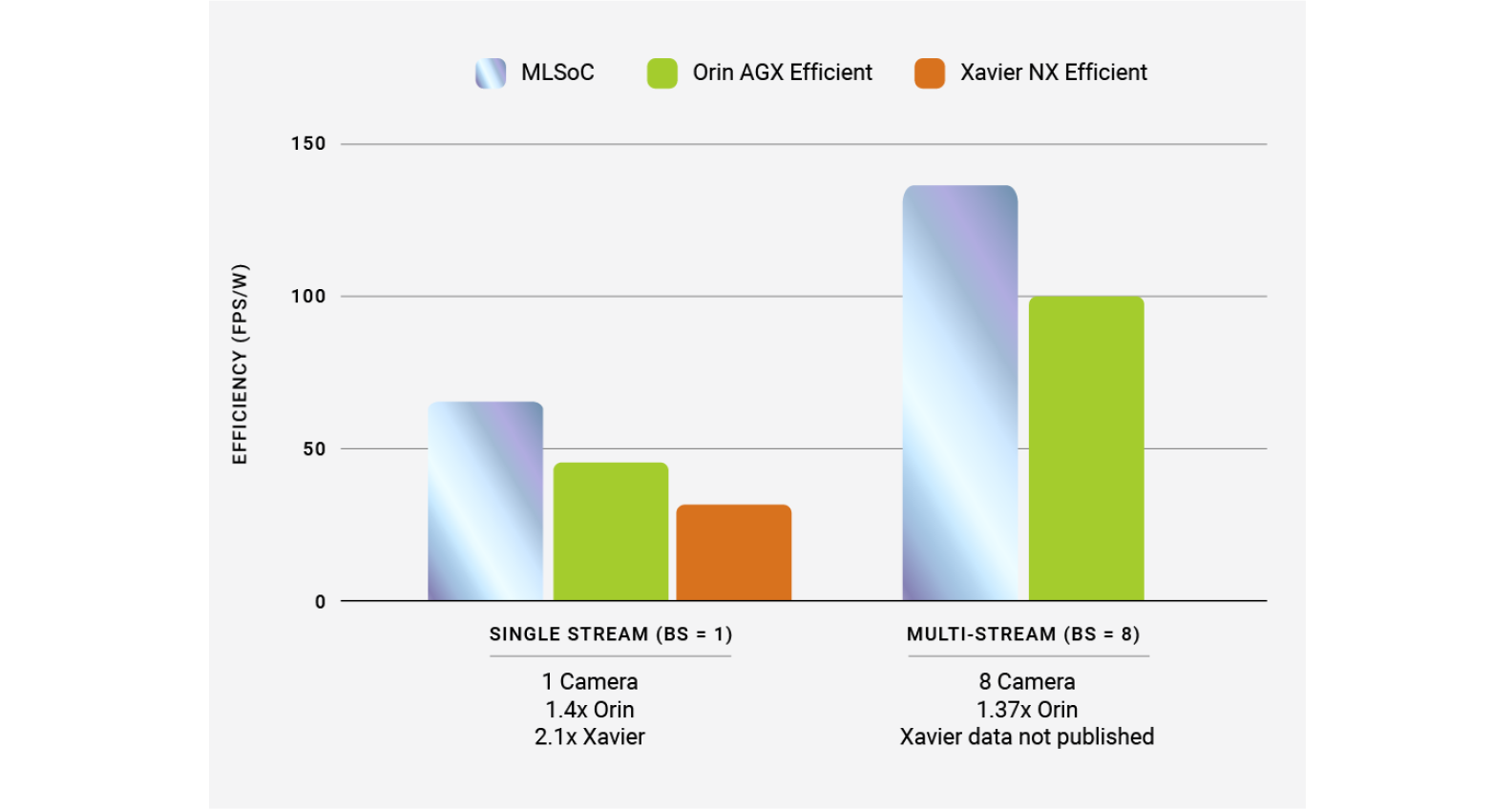 Comparing SiMa.ai's MLSoC DualM.2 Evaluation Kit with the NVIDIA Jetson AGX Orin (MaxQ, TensorRT) and the Auvidea JNX30 Xavier NX (MaxQ, TensorRT) using frames-per-second-per-watt derived from the MLPerf™ power metrics and batch sizes for Single Stream and MultiStream from Inference 3.0 Closed Edge Resnet50 results 3.0-0104 and 3.0-0081, and Inference v1.1 Single Stream result 1.1-118.
Comparing SiMa.ai's MLSoC DualM.2 Evaluation Kit with the NVIDIA Jetson AGX Orin (MaxQ, TensorRT) and the Auvidea JNX30 Xavier NX (MaxQ, TensorRT) using frames-per-second-per-watt derived from the MLPerf™ power metrics and batch sizes for Single Stream and MultiStream from Inference 3.0 Closed Edge Resnet50 results 3.0-0104 and 3.0-0081, and Inference v1.1 Single Stream result 1.1-118.
Why do these results matter for the industry and our customers?
Despite being on a process node that is two generations behind NVIDIA, SiMa.ai beat NVIDIA on performance and power using our fully automated ML compiler. SiMa.ai achieved this rare feat by architecting a purpose-built product from the ground up that is a combination of silicon and software that enables embedded edge customers to integrate machine learning with their legacy applications.
SiMa.ai's MLSoC technology offers a massive opportunity to customers to turbo charge their embedded edge applications by integrating machine learning capabilities. Industry wide this has the potential to dramatically advance machine intelligence and power one of the most significant potential technological shifts we will see this decade. If we can enable decision making in real time without consuming a lot of power, it will radically and rapidly advance how these types of devices perform intelligent tasks. It will allow these everyday devices that exist across virtually every industry, from smart manufacturing, to robotics, autonomous vehicles or healthcare, to move past expending their energy solely on thinking or interpreting what they are seeing and achieve something new.
With a new architecture that is purpose built for the edge as opposed to the data center, the door is wide open for a new age of intelligence in everyday products benefiting from AI and ML.Footnotes:
- Comparing power metrics for Inference v3.0 Closed Edge Resnet50 Single Stream and MultiStream results 3.0-0104 and 3.0-0081.
- Using power metrics from Inference v3.0 Closed Edge Resnet50 Single Stream result 3.0-0104.Result verified by MLCommons Association. MLPerf™ name and logo are trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See www.mlcommons.org for more information.
- Using power metrics from Inference v3.0 Closed Edge Resnet50 Single Stream result 3.0-0081. Result verified by MLCommons Association. MLPerf™ name and logo are trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See www.mlcommons.org for more information.
- Comparing power metrics for Inference v3.0 Closed Edge Resnet50 Single Stream and MultiStream results 3.0-0104 and 3.0-0081.
- Using the latency from Inference v3.0 Closed Edge Resnet50 Single Stream result 3.0-0104. Result verified by MLCommons Association. MLPerf™ name and logo are trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See www.mlcommons.org for more information.
- Using latency metric from Inference v3.0 Closed Edge Resnet50 MultiStream result 3.0-0104. Result verified by MLCommons Association. MLPerf™ name and logo are trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See www.mlcommons.org for more information.
- Comparing Single Stream and MultiStream latencies for Inference v3.0 Closed Edge Resnet50 results 3.0-0104 and 3.0-0081.